What is a Dataset?
Description of a BCO-DMO dataset and specific data types.
The BCO-DMO Dataset
As a federally-funded data repository, BCO-DMO aligns with the U.S. Office of Science and Technology Policy (OSTP) concept of data as outlined in its 2022 Memorandum "Ensuring Free, Immediate, and Equitable Access to Federally Funded Research" where: “scientific data” include the recorded factual material commonly accepted in the scientific community as of sufficient quality to validate and replicate research findings.
Such scientific data do not include laboratory notebooks, preliminary analyses, case report forms, drafts of scientific papers, plans for future research, peer-reviews, communications with colleagues, or physical objects and materials, such as laboratory specimens, artifacts, or field notes.
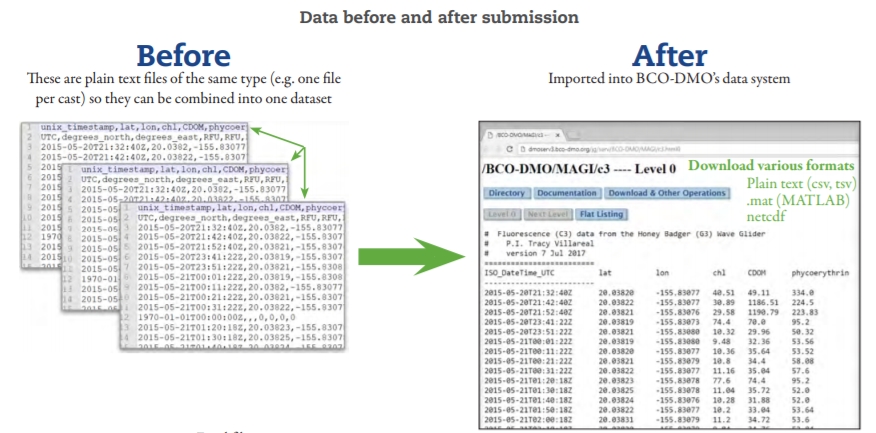
A BCO-DMO dataset usually consists of a file containing a single data table (example formats: csv, Excel, tsv) or a collection of files that contain the same type of data, like a collection of model output files in .netcdf format or a collection of coral quadrat photos.
Examples of datasets:
CTD data from one cruise or CTD data from several cruises that have been processed and analyzed in the same way.
A collection of images resulting from a model, along with the input files, and model code would constitute a BCO-DMO dataset.
Water quality parameters collected by hand using a multimeter, handheld fluorometer, and nitrate sensor from the same location, such as a pier, over a period of time.
Water biogeochemistry determined using several instruments from samples collected at sea, along with NCBI accession numbers of sequences obtained from biological samples collected at those same locations during the cruise.
Species names, sampling locations and dates, and specimen size and sex determined using a microscope from samples collected by various nets during several cruises pertaining to a research project.
Trace metal concentrations in water samples collected by Niskin bottles, McLane pumps, and ice corers deployed during a cruise.
Carbonate system parameters and mussel growth measurements resulting from a laboratory experiment on ocean acidification.
One dataset does not necessarily equate to one data file. A dataset may be made up of multiple data tables with the same organizational structure that are combined into one by the data table manager.
A single dataset is described by metadata presented within one BCO-DMO Dataset Landing Page. Therefore, submissions that describe different types of acquisition methods, processing methods, or parameters, or that were produced by different projects/awards would likely not be a single BCO-DMO dataset.
Dataset Types
BCO-DMO manages a wide variety of data types and formats. Contents of the datasets change depending on the subject, but the following information is required for every dataset for improved reusability of that dataset:
Dates, times, and timezone
Location information (latitude and longitude)
Tabular data with biological and chemical oceanographic data from in-situ measurements during cruises or field sampling, sediment samples, lab experiments, etc. make up the bulk of the BCO-DMO data holdings. See the "Organizing Data Tables" page for more details on the supported format and organization of tabular data.
Models, Software, & Code are rapidly emerging data types, with few community templates or formalized structures. See the Models, software & code guidelines pages that BCO-DMO is using to standardize these data submissions.
GEOTRACES data submitted to BCO-DMO need to follow a program-specific template. See the "GEOTRACES" page for details on data submission complying with the requirements of the this program.
Genetic Accessions: Genetic data are primarily curated in the domain-specific repository NCBI (https://ncbi.nlm.nih.gov/). However, BCO-DMO publishes the metadata related to the genetic accessions, using the specific identifier as a way to relate the data in NCBI and BCO-DMO. Specific information on this data type can be found on the "Genetic Accesions" page.
Image Classification Data: Images and ancillary data from imagery instruments. Our "Image Classification" data page is still being finished.
Metadata
Each dataset needs information providing sufficient context for peer review and reuse of the data. Therefore, each dataset needs to have its own metadata page, describing the who/what/where/how information about the data.
Metadata consists of detailed acquisition and processing descriptions, including a description of all instruments used, parameter descriptions, funding, investigator names and contact information, as well as links to related datasets and publications. See the full list of necessary metadata for a BCO-DMO dataset for all details.
Important aspects of research data should be documented as it's collected and analyzed making it easier to provide the necessary metadata. A robust data management plan at the start of the project can mapping this information.
Last updated