Models, Software, and Code
Instructions on contributing model output, software, and code to BCO-DMO
What to do with Code, Software and Models?
If you have code or software you developed as part of your project, check your funding agency's requirements for making your code public. If you were funded by NSF's OCE division you are required to make your code public within two years of developing it. If your code has already been documented and archived (i.e. citable with a DOI), we can link to it as a Related Publication from your Dataset Landing Page (see section below Making code citable with an archive). We encourage archiving your code and getting a dedicated DOI for it. If your code is not archived elsewhere, we can publish it from the Supplemental Files section of relevant BCO-DMO Dataset Pages and it will be archived in the same package as your data.
You can send us your code any way you choose, whether by attaching files to an email, uploading them to the submission tool (https://submit.bco-dmo.org/), sending us a repository link (e.g. GitHub), or sending us a DOI.
Code and software should be documented and commented to an extent that it is understandable to others. Full reproducibility isn't always possible but you should include enough detail that someone could follow along with what was done and be able to understand how it works and how the results were produced. The goal is transparency and transferable knowledge. The knowledge gained and techniques employed should be reproducible even if the exact workflow can't be.
Do I need GitHub or to know version control to follow this guidance?
While we encourage the use of version control (e.g. git), and a GitHub online repository, you don't need to use either to get your code archived and document it for long-term preservation. The sections below provide guidance with and without a github repository.
Code documentation: What to include
Whether you upload your files to an archive like Zenodo or submit them to us with your BCO-DMO dataset, you will have to include the following in your documentation to the greatest extent possible in order to ensure proper reusability of your code:
Provide a general description of what your code does and how it works.
Describe dependencies and prerequisites. Don't forget to include the version of the programming language you used.
Provide information about settings and configurations, if applicable.
Provide a description to go along with each file.
Describe what the file does if it is code.
If it is an input data file, describe where it came from, what is in it (e.g. CTD data from cruise KN1818 obtained from R2R, DOI: ####), and provide parameter names descriptions, and units (e.g. NH4, Pore water dissolved ammonium, micromolar (uM)).
For more information and examples, you can refer to "How to Write Good Documentation": https://guides.lib.berkeley.edu/how-to-write-good-documentation.
Comment lines within code are a recommended best practice, however, they do not take the place of the above recommendations.
Where do you put documentation? If you have a GitHub repository you can put documentation in your README.md file. Or you can put it in a supplemental file archived with your code. You can also provide it to BCO-DMO along with your data submission's methodology section or as a supplemental file.
Example of documentation as part of the GitHub README.md file: a README.md archived at Zenodo with package DOI: 10.5281/zenodo.4625160)
Example of documentation provided as a supplemental file at Zenodo (DOI: 10.5281/zenodo.7129648)
Example of documentation as a supplemental file attached to a BCO-DMO dataset: "OysterFutures simulation model" https://www.bco-dmo.org/dataset/875301.
My code is in GitHub, why does it need to go somewhere else?
GitHub and Bitbucket are code repositories but not archives. Code repositories are great for sharing and collaborating, but they can be taken down at any time by the authors or the repository. If you archive your code repository using Zenodo (or another archive), it will be preserved and you will get a digital object identifier (DOI) for your code. See "Making code citable with an archive" below.
Once you have your code archived you can supply the formal citation and DOI to journal publications and BCO-DMO along with dataset submissions.
While Zenodo does not have the same support for connecting to Bitbucket as it does for GitHub, you can still archive a copy of your Bitbucket repository at Zenodo by uploading your repository files directly. It is a good idea to make a tag in Bitbucket to document your code version and include the version information in your documentation when creating a Zenodo DOI.
Making code citable with an archive
If you would like to make your code persistent and citable you can archive your code using an archive such as Zenodo. You will then have a DOI and formal citation for your code. Make sure to document your code well for optimal reuse, see the above topic code documentation.
Adding software to Zenodo can be done by uploading files directly, or by linking a github repository.
Connect your GitHub repository to Zenodo to archive code releases:
See Github's "Making Your Code Citable" https://guides.github.com/activities/citable-code/.
Make sure to pay attention to the part of the guidance that explains to connect Zenodo to your GitHub repository before making the next GitHub release you want to archive.
After you connect a repository to Zenodo, each time you make a release in github it will automatically get archived and DOI'ed at Zenodo.
If you don't have a GitHub repository, you can upload your files directly to Zenodo. Step-by-step through on how to upload files directly to Zenodo: https://help.zenodo.org/docs/deposit/create-new-upload/
Examples of GitHub releases archived at Zenodo:
Dykman, L. (2021). ldykman/FD_EPR: GitHub repository release associated with Dykman et al. (2021) Ecology (Version v1.0.0). Zenodo. https://doi.org/10.5281/zenodo.4625160
Schenck, F. R. (2022). schenckf/BWE_Experiment: The effect of warming on seagrass wasting disease depends on host genotypic identity and diversity - Analyses (Version V2.0.0) [Computer software]. Zenodo. https://doi.org/10.5281/zenodo.7129500
Don't forget to add a LICENSE
Code licenses provide specific boundaries on how others are allowed to reuse your code and credit. The MIT license is often used for open-source software. Whichever license you use, make sure that the license will satisfy funder sharing requirements.
To add a license directly to a Zenodo submission by creating a text file (typically named LICENSE or LICENSE.txt), copy the text of the license into the file (make sure to replace the year to the current year the names of the copyright holders) and upload it to Zenodo with your code.
To add a license to your code in GitHub, follow this walk through to add a license. https://docs.github.com/en/communities/setting-up-your-project-for-healthy-contributions/adding-a-license-to-a-repository
When BCO-DMO publishes code as supplemental files along with a dataset. The data and code are published with the same license, Creative Commons Attribution 4.0.
I'm using someone else's code that isn't public or archived
We understand the reality that datasets are sometimes produced using code that isn't publicly available. Whether it is proprietary software from an instrument manufacturer or if you used code provided by a colleague that isn't published in a way that follows best practice recommendations for long-term archiving. When you submit a dataset to BCO-DMO provide whatever information you have about the code. - Who are the authors? Provide real names not just usernames if you have them. - Briefly describe what the code does. - How do you get the code/software? Is it publicly accessible? If so, where can it be found? Or is it available upon request or purchase from the authors or company? - What version of the code did you use? Or lacking that, what date did you use the code? If it is public on GitHub, provide the link to the repository and the version (or commit) you used if available. If you know the authors of public, but not archived code, encourage them to publish their code with documentation, a release, and a license. (See "Making Your Code Citable" https://guides.github.com/activities/citable-code/). They get a formal citation they can put on their CV after archiving it which is a great incentive, not to mention enhanced discoverability and usage.
Models
Please include these topics in your documentation to the greatest extent possible:
Provide a general description of what the model does.
Supply input data and files, settings, and configurations.
Describe the results and output of model runs.
Describe the format of the output files, what kind of data are in them, and the parameter descriptions and units (e.g. temperature of the surface layer, degrees Celsius).
If you used a community-developed model (e.g. ROMS), please cite the model you used along with the version number, if possible. Provide a link where documentation can be found for the model.
If you developed your model as part of your project, refer to the above guidance for submitting software/code to BCO-DMO.
How much model output should we publish at BCO-DMO?
We can publish the full set of output files. However, if the full output can be easily recreated from the files and methodology you provide, it would be fine to only publish one output file as an example. If publishing the full output would be valuable to your community to make things easier for others' research, that would be another reason to publish the full output.
Metadata for datasets produced with your code
Include a general description of how your dataset was produced using your code.
Example: "..the column Functional Guild was generated by hierarchical clustering in R using the function gowdis in the package FD as described in Dykman et al. (2021). Scripts to run these analyses are available at Zenodo (Dykman, 2021, DOI: 10.5281/zenodo.4625160)."
Document the version of your code used to produce the dataset you are submitting to BCO-DMO. This lets us connect the exact version of your code to the exact data version we publish at BCO-DMO.
Provide a version number, commit, release, or DOI. This lets us connect the exact version of your code to the exact data version we publish at BCO-DMO.
If it is related code used to analyze (or plot) your dataset for a subsequent journal publication, state what version of the code was used for the journal publication.
Example: "...All code was written and run in R (version 3.6.1, www.R-project.org). Github repository https://github.com/schenckf/BWE_Experiment V2.0.0 archived at Zenodo (DOI: 10.5281/zenodo.7129500). A general description of the code is included in the repository release in file "Analysis Description.docx."
Supply any settings and configurations used to produce your dataset.
Document the versions of the language and packages you used. e.g.
R version 3.4.1 (2017-06-30), packages;vegan v2.5.4 (Oksanen et al. 2019), ggplot2 v3.2.1 (Wickham 2016).[If applicable] Provide input/config files. We can publish these as supplemental files attached to the dataset.
Citing Packages and Sofware Versions
Where possible, provide the exact package and software version numbers you used to generate your data and the recommended citation for your software.
Example of citing the language version:
These data were produced using code run with R version 3.4.1 (2017-06-30).
Example of software cited in methodology text: From the dataset "Tidal study of seawater microbial communities" https://www.bco-dmo.org/dataset/783679
To understand the variability in microbial communities over time at all sites, Bray-Curtis dissimilarity was calculated between each sample in the R package vegan v2.5.4 (Oksanen et al. 2019) and illustrated using non-metric multidimensional scaling (NMDS) in the R package, ggplot2 v3.2.1 (Wickham 2016).
References:
Wickham H (2016). ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York. ISBN 978-3-319-24277-4, https://ggplot2.tidyverse.org. https://doi.org/10.1007/978-3-319-24277-4
Oksanen J, Blanchet FG, Friendly M, Kindt R, Legendre P, McGlinn D, Minchin PR, O’Hara RB, Simpson GL, Solymos P, Stevens HH, Szoecs E, Wagner H (2019) Vegan: Community Ecology Package. R package version 25-4. Available from https://cran.r-project.org/package=vegan https://cran.r-project.org/src/contrib/Archive/vegan/vegan_2.5-4.tar.gz
Note that the reference Wickham (2016) for ggplot2 doesn't include the version. But the methods text does include the exact version number that was used to produce the dataset.
If you have a lot of installed packages you can supply a supplemental file with the packages and version numbers you used instead of citing them all in your methods text.
Getting versions in R
To print the R version associated with a project in RStudio:
To get the version of a package you imported (dplyr is the name of an example package) :
To print package information about all loaded packages (including package version), use the installed.packages() function.
This function returns a matrix containing one row per loaded package. The matrix shows "Package", "LibPath", "Version", "Priority", "Depends", "Imports", "LinkingTo", "Suggests", "Enhances", "OS_type", "License" and "Built".
Since this is a matrix, you can specify which columns, and therefore which metadata is returned. For example, if you want the package name and the version for each package, you would run:
To print all high-level system information in RStudio:
In this output, the standard or base packages are listed under "attached base packages." These packages are loaded by R by default and do not need to be called into the project.
"Other attached packages" are those that are loaded into a project using the library() function.
Packages listed under "loaded via a namespace" are those imported automatically by R as dependencies of "other attached packages."
Getting versions in Python
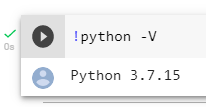
To get your Python version using the command line:
To get the version of a package you imported you can use packagename.__version__
There are several ways to get all package versions in your environment. See pip "list" "freeze" or "show" in pip documentation.
Getting versions in Matlab
You can get the version of Matlab and installed packages with the command ver:
Last updated